
Par Jacqueline Whyte Appleby, L’Ontario Council of University Libraries (OCUL)
L’Ontario Council of University Libraries (OCUL) est un consortium de bibliothèques universitaires composé de membres. En 2024, l’OCUL a lancé le programme OCUL Artificial Intelligence and Machine Learning (AIML), qui vise à promouvoir une utilisation responsable et éthique de l’AIML dans l’environnement des bibliothèques universitaires tout en renforçant les connaissances et les compétences connexes parmi les membres de l’OCUL et au-delà. Le programme comprend cinq projets distincts. Un des projets, qui vise à améliorer l’accès aux collections de documents gouvernementaux grâce à des métadonnées générées par l’IA, fait partie du Consortium sur l’IA générative du COQES. Visitez le site web de l’OCUL pour plus d’informations sur le programme et les projets AIML de l’OCUL.
C’est désormais bien connu : nous sommes submergés d’informations. Les fausses informations, la désinformation et les « infox » abondent, mais l’explosion de l’édition en ligne entraîne également un déluge d’informations de qualité! Une recherche sur le terme « remède contre le cancer » sur le site des bibliothèques de la University of Toronto donne plus de 84 000 résultats, dont 47 000 articles de revues évaluées par des pairs, 3 400 chapitres de livres et 1 500 thèses de doctorat. Comment trouver les ressources qui correspondent à nos questions précises? Comment savoir si nous devons approfondir un article particulier?
La réponse, bien sûr, réside dans les métadonnées! Les métadonnées, c’est-à-dire les données sur les données, sont partout autour de nous et sont essentielles à notre processus de compréhension. Lorsque vous regardez un film à l’affiche, vous voulez connaître sa durée pour planifier votre soirée. Lorsque vous ouvrez un numéro de The Economist, connaître sa date de publication est essentiel pour comprendre ce que vous allez lire.
Les bibliothèques sont des centres de production, d’agrégation, d’harmonisation et de structuration des métadonnées. Rendre nos ressources faciles à trouver et compréhensibles est au cœur de notre travail. Lorsque les métadonnées sont insuffisantes, la découvrabilité devient un défi. Les métadonnées comprennent presque toujours les informations de base telles que le titre, l’auteur et l’année de publication, mais pour être vraiment utiles, elles devraient également inclure les sujets traités, des mots-clés soigneusement sélectionnés, des informations sur le financement, les affiliations des auteurs, des identifiants uniques (le numéro ISBN d’un livre, par exemple) et plus encore.
La création de métadonnées aussi détaillées prend énormément de temps. Lorsque les bibliothèques achètent des ressources, c’est généralement l’éditeur ou le distributeur qui se charge de ce processus. Mais qu’en est-il des contenus gratuits, ouverts, numérisés ou nouvellement produits? Les outils basés sur l’IA générative offrent des possibilités d’améliorer ce processus.
« Improving Access to Digital Collections Using GenAI in Libraries » est un projet soutenu par le COQES et mené par l’Ontario Council of University Libraries (OCUL) et Scholars Portal, le service numérique de l’OCUL. Ce projet est l’un des cinq projets menés dans le cadre du programme AIML de l’OCUL. Notre équipe de projet comprend des bibliothécaires, des développeurs, des spécialistes du soutien aux systèmes et des étudiants en coopération. Nous souhaitons explorer l’application de l’IA générative et des technologies de reconnaissance optique de caractères (ROC) afin d’améliorer la qualité des métadonnées et la facilité de recherche des collections numériques des bibliothèques. Le projet permettra d’enrichir près de 50 000 documents gouvernementaux que les bibliothèques de la University of Toronto ont numérisés et mis à la disposition du public sur Internet Archive. Ces documents, qui comprennent des rapports, des notes d’information, des budgets et des enquêtes, constituent une mine d’informations sur l’histoire et les politiques publiques, mais en tant que documents historiques, ils manquent souvent de métadonnées qui aideraient les chercheurs à comprendre leur contenu ou leur utilité.
Voici un exemple de ce que vous pourriez trouver en parcourant la première page de la collection sur archive.org :
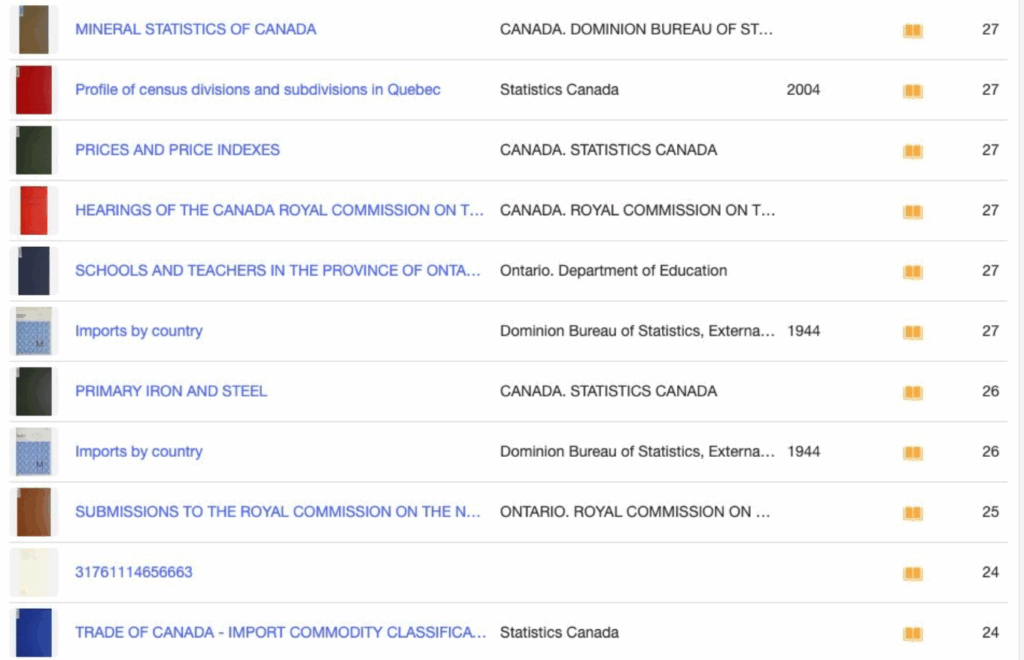
Quatre de ces ressources ne comportent aucune métadonnée, pas même un titre. Et bien que Statistique Canada ait produit quatre de ces documents, ils ont été nommés de trois façons différentes, ce qui ne garantit pas qu’ils apparaîtront ensemble lors d’une recherche. Nous avons également deux ouvrages intitulés « Comptes des flux financiers » — font-ils partie d’une série? Quels sont les liens entre eux?
Voici un exemple d’une série clairement définie résultant d’une recherche par titre :
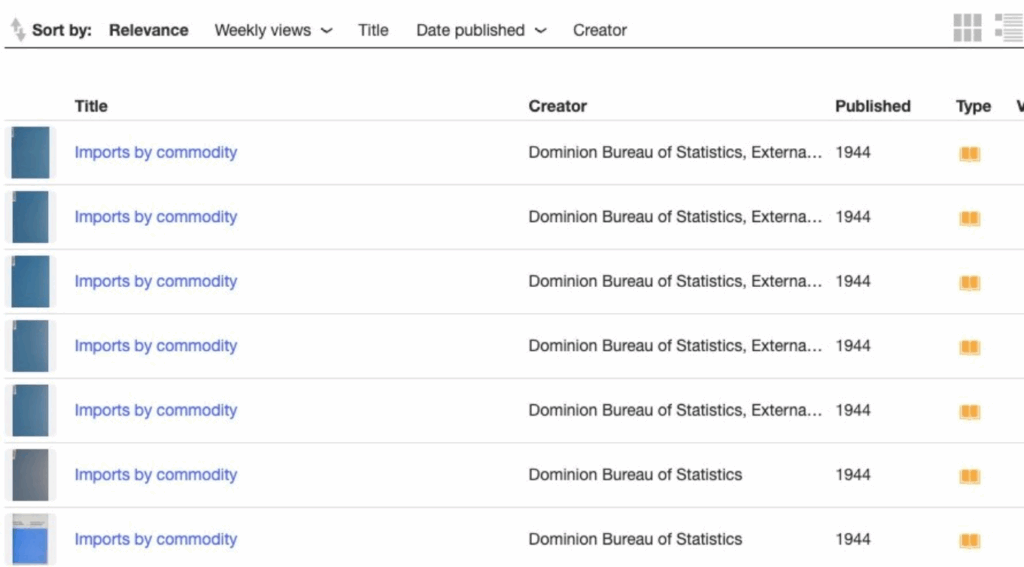
Mais alors que le document Imports by Commodity est un rapport gouvernemental produit annuellement, les métadonnées de chacun de ces documents ont la même date de publication (1944), de sorte qu’il faut ouvrir chaque document pour savoir de quelle année il s’agit.
En creusant jusqu’au niveau des documents, nous trouvons de grandes quantités d’informations historiques. Voici un exemple tiré d’un Importations par pays, janvier-décembre 1972 :
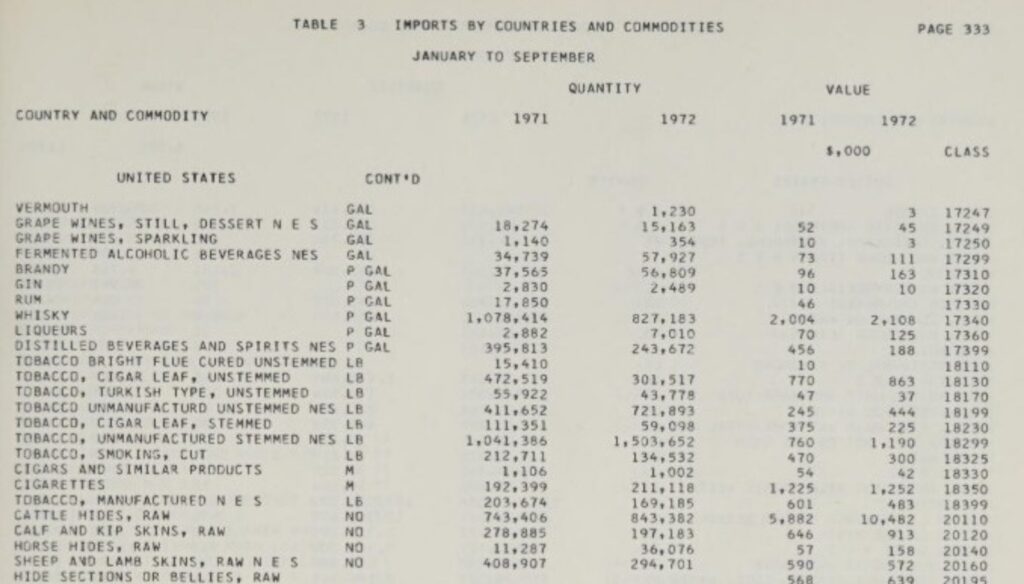
Les importations historiques de whisky en provenance des États-Unis semblent être un sujet d’intérêt ces jours-ci. Mais il faudrait avoir une bonne connaissance du sujet ou parcourir toutes ces pages pour savoir que cela s’est produit.
La numérisation a toujours promis la recherche en texte intégral, mais la qualité de ces numérisations rend cela impossible dans certains cas. Et pour créer des métadonnées utiles pour ces documents, nous devons d’abord comprendre ce que contient le texte. La technologie ROC est utilisée depuis longtemps pour convertir des images numérisées en texte, mais elle n’est pas parfaite, et la ROC généré à partir des numérisations de cette collection est quelque peu chaotique!
Voici le même tableau des produits de base en texte clair à droite :

Bien qu’il soit possible de comprendre qu’il s’agit d’un tableau, certaines données sont mal représentées ou manquent complètement.
Et beaucoup sont bien pires que cela! Voici la page d’index du rapport « Importations par pays » de 1972 dans le lecteur, après un premier passage par la ROC :

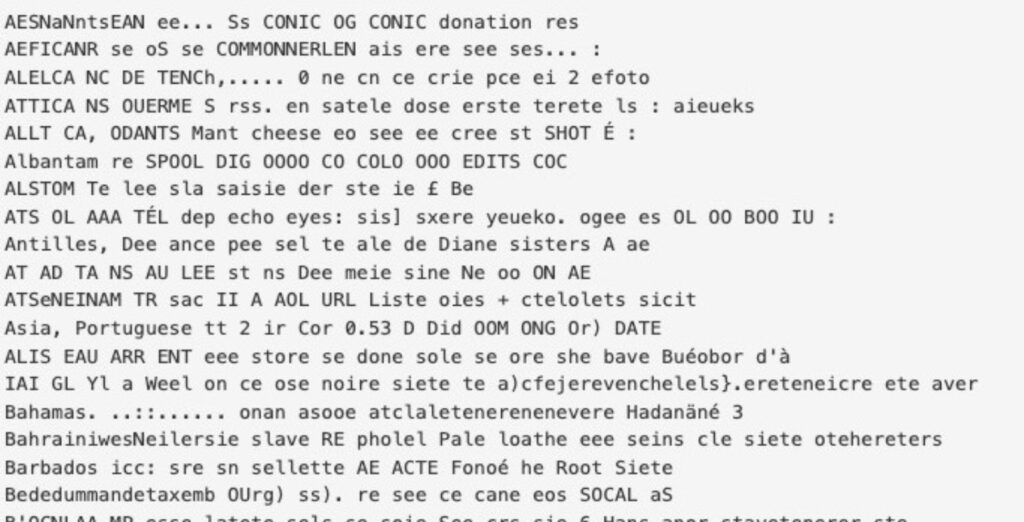
Après quelques essais, nous avons réalisé que la ROC lisait en fait à travers la page fine, en extrayant les caractères de la page suivante.
La première étape de ce projet concerne les métadonnées, mais l’objectif à long terme est de pouvoir interroger ce corpus de documents à grande échelle, en posant des questions sur l’ensemble des documents et en trouvant des liens entre eux à l’aide d’une base de données vectorielle et d’une génération augmentée par la récupération. Pour réussir tout cela, nous devons nous assurer que notre ensemble de données représente fidèlement ce qui se trouve dans les documents.
Le travail fondamental de ce projet consiste à tester différents outils de reconnaissance optique de caractères (ROC) afin de déterminer le bon équilibre entre précision, vitesse et puissance de calcul, car même l’outil le plus précis ne fonctionnera pas s’il ne peut pas être adapté à notre corpus de documents. L’outil le plus simple, Tesseract fonctionne bien pour les documents de base, mais se heurte à la complexité de la mise en page de bon nombre de ces rapports. Des outils plus sophistiqués utilisant de grands modèles de langage (GML) sont capables de capturer le texte et la structure avec plus de précision, mais ils sont lents et gourmands en ressources. Marqueur de ROC, olmOCR et smolDocling sont trois des outils alimentés par l’IA avec lesquels nous travaillons, mais le calcul n’est pas toujours simple. Étant donné que les documents gouvernementaux se présentent sous divers formats, tailles et structures (par exemple, brochures contenant de nombreuses images, documents budgétaires volumineux ou comptes rendus parlementaires où l’anglais et le français apparaissent dans deux colonnes parallèles), certains outils seront plus adaptés à certains types de documents, indépendamment de la taille de leur GML ou de leur vitesse.
À mesure que nous progressons dans la ROC et commençons à extraire les métadonnées, nous sommes impatients de partager ce travail avec vous!
Pour en savoir plus sur l’OCUL et le Programme AIML de l’OCUL ici. Consultez la page web du COQES pour plus d’informations sur le Consortium sur l’IA générative et les autres projets concernés.
À propos de l’OCUL et du Scholars Portal
Grâce à l’Ontario Council of University Libraries (OCUL) et à son service numérique, le Scholars Portal, les bibliothèques universitaires de la province ont accès à des services partagés et à une infrastructure technologique qui soutiennent leur enseignement, leur recherche et leur apprentissage. Ensemble, le Scholars Portal et l’OCUL répondent aux besoins des établissements d’enseignement postsecondaire en leur offrant des services d’information innovants et en garantissant l’accès à la recherche et au contenu ainsi que leur préservation.