
By Jacqueline Whyte Appleby, Ontario Council of University Libraries (OCUL)
The Ontario Council of University Libraries (OCUL) is a member-based consortium of academic libraries. In 2024, OCUL launched the OCUL Artificial Intelligence and Machine Learning (AIML) Program, which aims to promote responsible, ethical AIML use in the academic library environment while building related knowledge and skills across the OCUL membership and beyond. The program consists of five distinct projects. One of the projects, focused on enhancing access to government documents collections through AI-generated metadata, is part of HEQCO’s Consortium on Generative AI. Visit the OCUL website for more information on OCUL’s AIML program and projects.
It’s a well-trod maxim at this point: there’s too much information out there. Misinformation, disinformation and fake news abound — but with the explosion of online publishing, there’s an overwhelming deluge of high-quality information too! Searching for “cancer cure” on the University of Toronto Libraries site brings up over 84,000 resources, including 47,000 peer-reviewed journal articles, 3,400 book chapters and 1,500 PhD theses. How do we find the resources that are right for our particular line of questioning? How will we know when we should delve deeper into a particular article?
The answer, of course, is metadata! Metadata, data about the data, is all around us, and is essential to our sense-making process. When you look up a movie playing in theatres, you want to know the runtime to plan your evening. When you open an issue of The Economist, knowing its publication date is essential context for whatever you read next.
Libraries are hubs of metadata production, aggregation, harmonization and structuring — making our resources findable and understandable is at the heart of our work. Where metadata is poor, discoverability will be a challenge. Metadata nearly always includes the basics such as title, author and year of publication, but to be really useful, it should also include subjects covered, carefully selected keywords, funding information, author affiliations, unique identifiers (a book’s ISBN, for example) and more.
Creating metadata with this much detail is extremely time consuming. When libraries buy resources, the publisher or distributor is typically in charge of this process. But what about for free, open, digitized or newly produced content? Tools powered by generative AI present opportunities for improving this process.
“Improving Access to Digital Collections Using GenAI in Libraries” is a HEQCO-supported project being run by the Ontario Council of University Libraries (OCUL) and Scholars Portal, the digital service arm of OCUL. This project is one of five taking place as part of OCUL’s AIML program. Our project team includes librarians, developers, systems support specialists and co-op students. We aim to explore the application of generative AI and optical character recognition (OCR) technologies to improve the metadata quality and discoverability of libraries’ digital collections. The project will enrich nearly 50,000 government documents that the University of Toronto Libraries has digitized and made openly available on the Internet Archive. These documents, which include reports, briefings, budgets and inquiries, are a treasure trove of history and public policy, but as historical documents, they are often lacking metadata that would help researchers understand what they contain or why they might be useful.
Here is an example of what you might find while browsing the first page of the collection on archive.org:
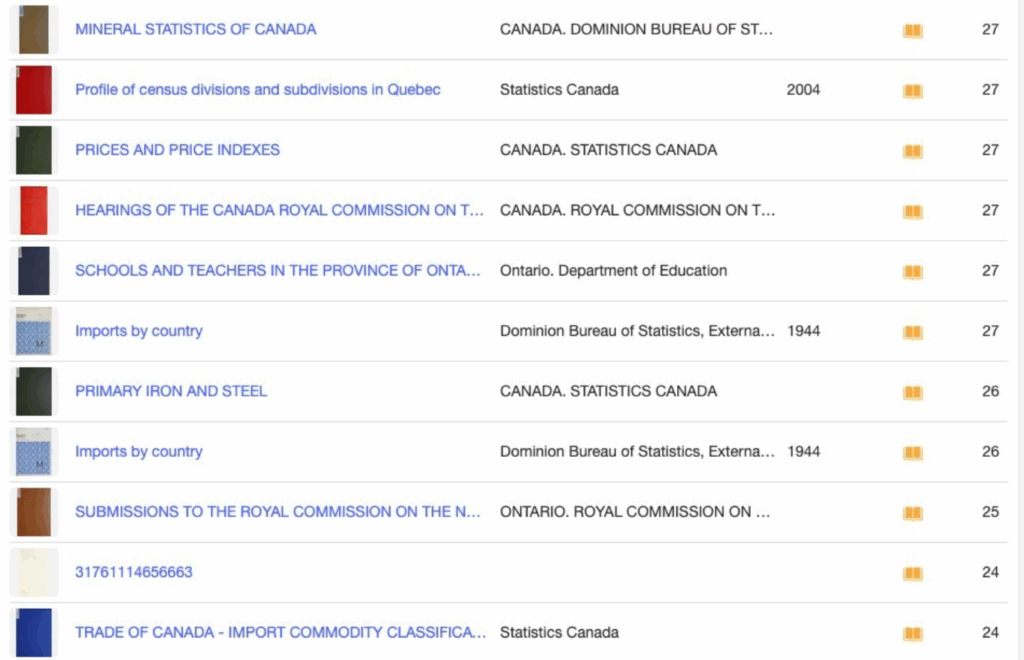
Four of these resources don’t have any metadata at all, not even a title. And while Statistics Canada is the producer of four of these documents, they’ve been named three different ways, so there’s no guarantee they’d come up together in a search. We also have two works titled “Financial Flow Accounts” — are these part of a series? How are they related to each other?
Here is an example of a clearly defined series resulting from a title search:
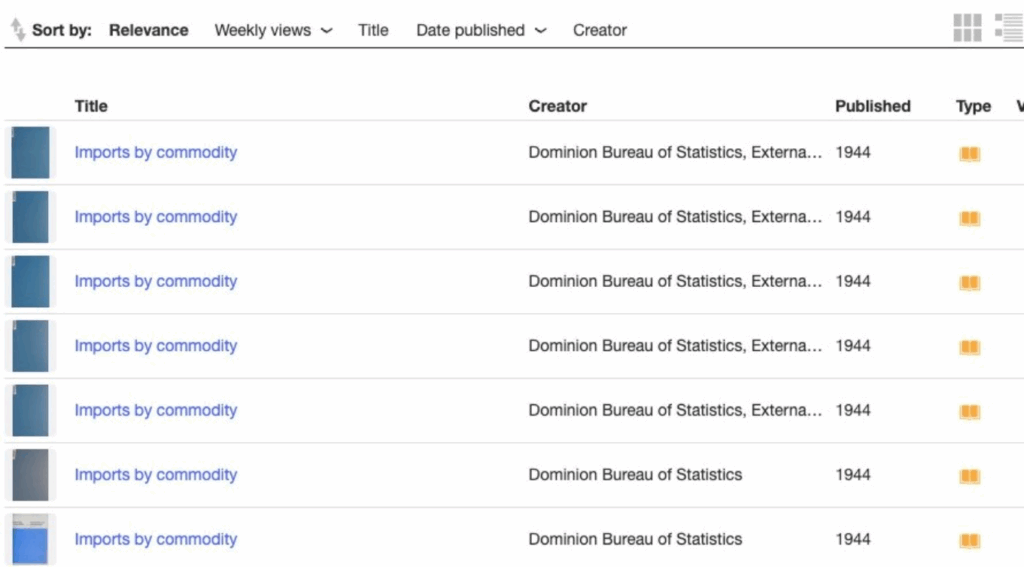
But while Imports by Commodity is a government report produced annually, the metadata for each of these documents has the same publication date (1944), so you’d need to open each document to know what year it’s reporting on.
Digging down to the document level, we see vast amounts of historical information. Here’s an example from Imports by Country, January–December 1972:
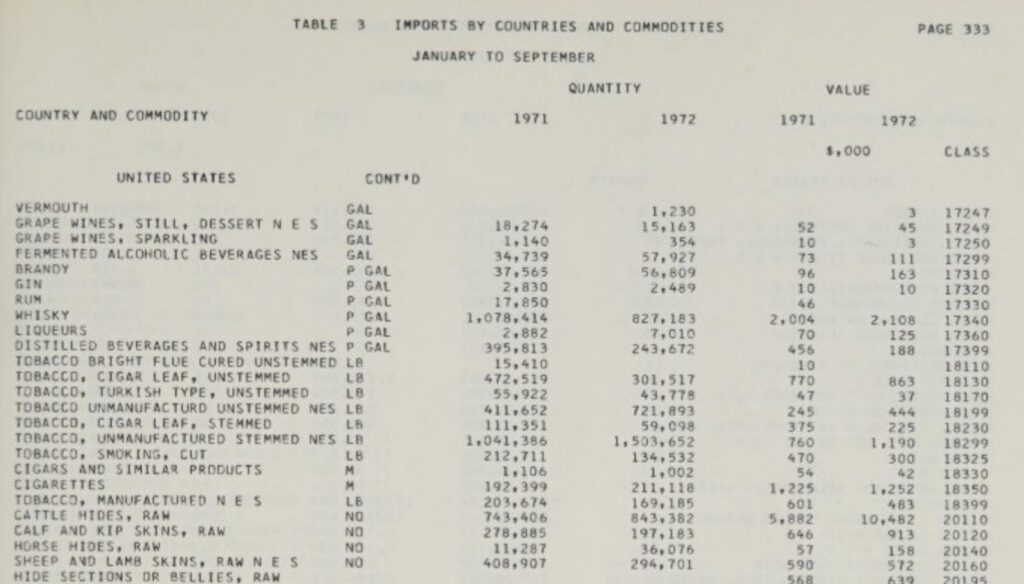
Historical whisky imports from the US seem like something that might be of interest these days. But you’d have to have a fair amount of subject-matter expertise, or look through all these pages, to know it was here.
The promise of digitization has always been full-text searching, but the quality of these scans means this isn’t always possible. And in order to create useful metadata for these documents, we first need to understand what the text is. OCR has long been used to convert scanned images into text — but it’s not a perfect technology, and the OCR generated with the scans for this collection is a bit of a mess!
Here is that same commodities table rendered as plain text on the right:

While it’s possible to understand that this is a table, some of the data points are misrepresented or entirely missing.
And many are much worse than this! Here’s the Index page for the 1972 Imports by Country report in the reader, and after an initial pass through OCR:

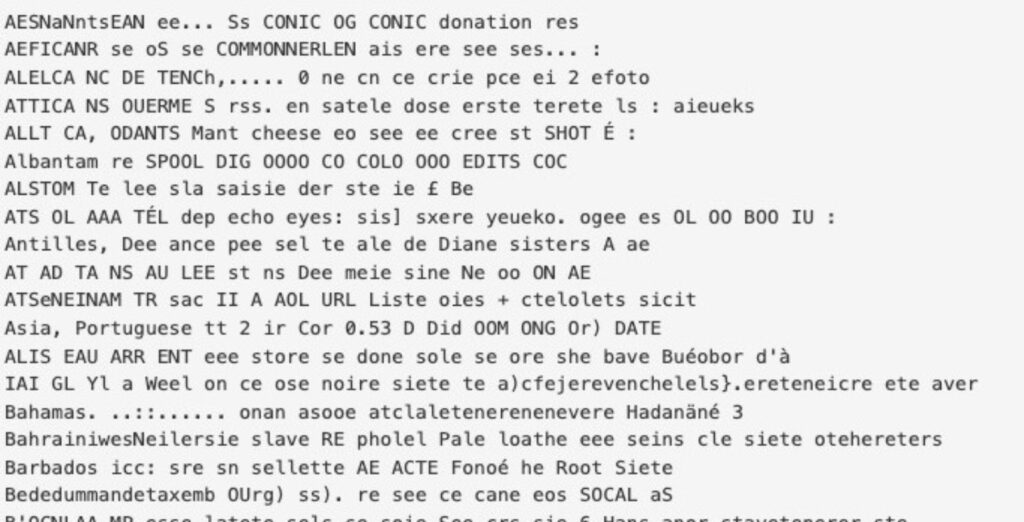
After some troubleshooting, we realized the OCR is actually reading through the thin page, pulling characters from the following page.
Step one of this project is metadata, but the long-term goal is to be able to query this corpus of documents at scale — asking questions across documents and finding links between them using a vector database and retrieval-augmented generation. To do any of this successfully, we need to be sure our dataset accurately portrays what’s in the documents.
The essential foundational work of this project is testing different OCR tools to determine the right balance of accuracy, speed and computer requirements, because the most precise tool won’t work if it can’t be scaled for our document corpus. The simplest tool, Tesseract, works well for basic documents, but struggles with the complex layout of many of these reports. More sophisticated tools that make use of large language models (LLMs) are able to capture text and structure with more precision, but they’re slow and resource intensive. Marker OCR, olmOCR and smolDocling are three of the AI-powered tools we’re working with — but it’s not always a simple calculation. Because government documents come in many formats, sizes and structures (for example, image-heavy pamphlets, large budget documents or Parliamentary proceedings where English and French run in two parallel columns), some tools will work better for some kinds of documents, regardless of the size of their LLM or speed.
As we move ahead with OCRing and begin extracting metadata, we look forward to sharing that work with you!
Learn more about OCUL and the OCUL AIML Program here. And check out HEQCO’s webpage for more information about the Consortium on Generative AI and the other projects involved.
About OCUL and Scholars Portal
Through the Ontario Council of University Libraries (OCUL) and its digital service, Scholars Portal, the province’s university libraries have access to shared services and technology infrastructure that support their academic teaching, research and learning. Together, Scholars Portal and OCUL respond to the needs of postsecondary institutions through innovative information services and ensuring access to and preservation of research and content.